现在计算机都是各种多核、异构的计算单元组成的,每一个单元都有多个处理核心。所以充分利用计算资源就显得至关重要,例如并行计算的程序、技术和工具等。
![图片[1]-什么是Python并行编程,并行计算的内存架构详解-不念博客](https://www.bunian.cn/wp-content/uploads/2023/03/image-35.png "什么是Python并行编程,并行计算的内存架构详解")
并行编程介绍
并行编程是一种编程方式,其中多个线程(或进程)同时执行不同的任务。这可以帮助提高程序的性能和吞吐量,因为它可以利用多核处理器和多核计算机的优势。
并行编程的优点:
- 提高性能和吞吐量
- 利用多核优势
- 更好地管理资源
- 利用分布式进行计算
并行编程的缺点:
- 会增加程序的复杂性
- 需要解决同步和死锁问题
- 增加了额外的调试成本
- 需要解决资源竞争问题
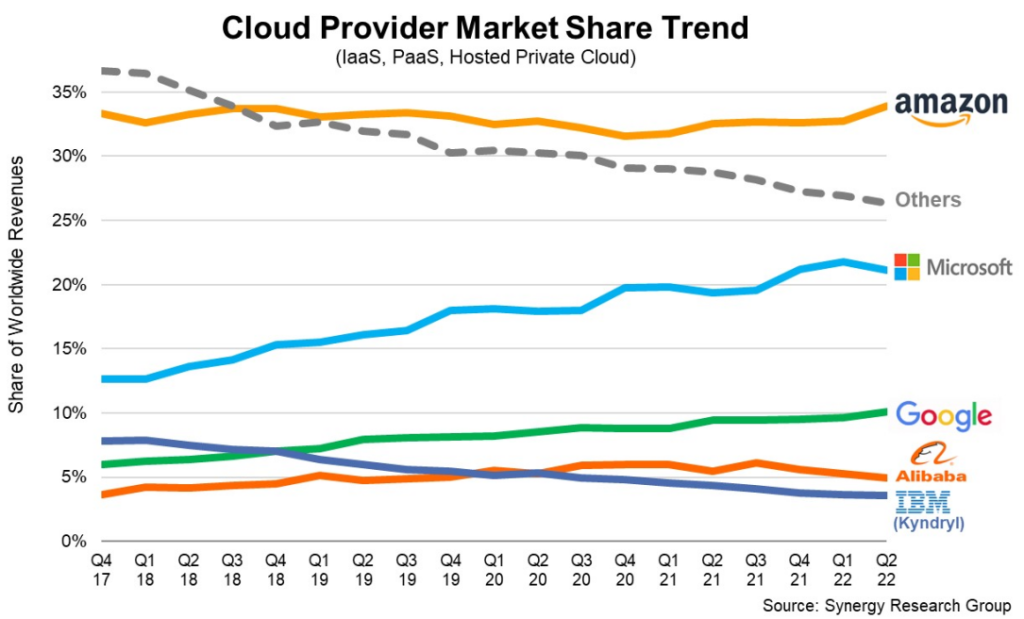
并行计算的内存架构
并行计算的内存架构主要分为两种:
- 共享内存架构:多个处理器共享同一块内存,可以直接访问和修改共享内存中的数据,这样可以减少数据传输的时间和提高程序的效率。
- 分布式内存架构:每个处理器有自己的独立内存,需要通过网络进行数据传输,这样可以更好地利用分布式系统的优势,但需要处理网络通信的开销。
此外根据指令的同时执行和数据的同时执行,计算机系统可以分成以下四类:
- 单处理器,单数据 (SISD)
- 单处理器,多数据 (SIMD)
- 多处理器,单数据 (MISD)
- 多处理器,多数据 (MIMD)
SISD
SISD (Single Instruction, Single Data) 是一种计算机体系结构,指的是一个处理器执行一条指令,对应一个数据进行操作的模式。
传统的单处理器计算机都是经典的SISD系统,运行在这些计算机上的算法是顺序执行的(连续的),不存在任何并行。
SIMD
MISD(Multiple Instruction stream Single Data stream )是并行计算机的一种结构。MISD具有N个处理单元,按N条不同指令的要求对同一数据流及其中间结果进行不同的处理。一个处理单元的输出又作为另一个处理单元的输入。
MISD实际上是指令层面的并行,多个指令在相同的数据上操作。能够合理利用这种架构的问题模型比较特殊,例如数据加密等。MISD在现实中并没有很多用武之地,更多的是作为一个抽象模型的存在。
SIMD
SIMD(Single Instruction, Multiple Data)采用一个控制器来控制多个处理器,同时对一组资料中的每一个分别执行相同的操作从而实现空间上的并列性的技术。
SIMD包括多个独立的处理器,每一个都有自己的局部内存,可以用来存储数据,所有的处理器都在单一指令流下工作。所有的处理器同时处理每一步,在不同的数据上执行相同的指令。SIMD架构比MISD架构要实用的多,很多问题都可以用SIMD计算机的架构来解决。
MIMD
MIMD(Multiple Instruction Stream Multiple Data Stream)具有多个异步和独立工作的处理器。在任何时钟周期内,不同的处理器可以在不同的数据片段上执行不同的指令。
MIMD比SIMD的计算能力更强。每一个处理器都在独立的控制单元分配的指令流下工作;因此,处理器可以在不同的数据上运行不同的程序,这样可以解决完全不同的子问题甚至是单一的大问题。
并行编程内存管理
无论处理单元多快,如果内存提供指令和数据的速度跟不上,系统性能也不会得到提升。
- 共享内存系统,共享内存系统有大量的虚拟内存空间,而且各个处理器对内存中的数据和指令拥有平等的访问权限。
- 分布式内存模型,在这种内存模型中,每个处理器都有自己专属的内存,其他处理器都不能访问。
并行编程模型
并行编程模型表示软件执行并行计算时必须实现的方式:为了访问内存和分解任务,每一个模型都以它独自的方式和其他处理器共享信息。
共享内存模型
所有任务都共享一个内存空间,对共享资源的读写是 异步的。系统提供一些机制,如锁和信号量,来让程序员控制共享内存的访问权限。
多线程模型
单个处理器可以有多个执行流程,多个线程会对共享内存进行操作,所以进行线程间的同步控制是很重要的。
消息传递模型
消息传递模型通常在分布式内存系统中应用。更多的任务可以驻留在一台或多台物理机器上。
数据并行模型
数据并行模型有多个任务需要操作同一个数据结构,但每一个任务操作的是数据的不同部分。在分布式内存架构中则会将数据分割并且保存到每个任务的局部内存中。
Python中线程与进程
Python既支持多进程,又支持多线程。线程是最小的执行单元,而进程由至少一个线程组成。如何调度进程和线程,完全由操作系统决定,程序自己不能决定什么时候执行,执行多长时间。
| 耗时分析 | CPU密集 | IO密集 | 网络密集 |
| 线性运算 | 94 | 22 | 7 |
| 多线程 | 101 | 24 | 1 |
| 多进程 | 53 | 12 | 1 |
多线程在IO密集型的操作下没有很大的优势,在CPU密集型的操作下明显地比单线程线性执行性能更差,但是对于网络请求这种忙等阻塞线程的操作,多线程的优势显著。
多进程无论是在CPU密集型还是IO密集型以及网络请求密集型中,都能体现出性能的优势。不过在类似网络请求密集型的操作上,与多线程相差无几,但却更占用CPU等资源。
如果多线程的进程是CPU密集型的,多线程并不能有多少效率上的提升,相反还可能会因为线程的频繁切换,导致效率下降,推荐使用多进程。如果是IO密集型,多线程进程可以利用IO阻塞等待时的空闲时间执行其他线程,提升效率。
Python并行编程库
Ray
Ray支持许多分布式机器学习库,但并不仅限于机器学习任务,任何 Python 任务都可以使用 Ray 分解并跨系统分布。
Dask
Dask使用集中式调度程序来处理集群的所有任务,会自动将它们的执行分散到您的集群中。
Dispy
dispy支持在集群、网格或云中的许多机器之间跨单个机器中的多个处理器并行执行计算。dispy 非常适合数据并行的场景。
ipyparallel
https://github.com/ipython/ipyparallel
ipyparallel专门用于跨集群并行执行 Jupyter notebook 代码,它将任何函数应用于一个序列,并在可用节点之间平均分配工作。
Joblib
https://github.com/joblib/joblib
Joblib 是一组在 Python 中提供轻量级流水线的工具,通过使用 numpy.memmap,可以在同一系统上的进程之间在内存中共享数据区域。