TOPSIS(Technique for Order of Preference by Similarity to Ideal Solution)是一种多准则决策分析方法,可用于对方案或样品进行评价。
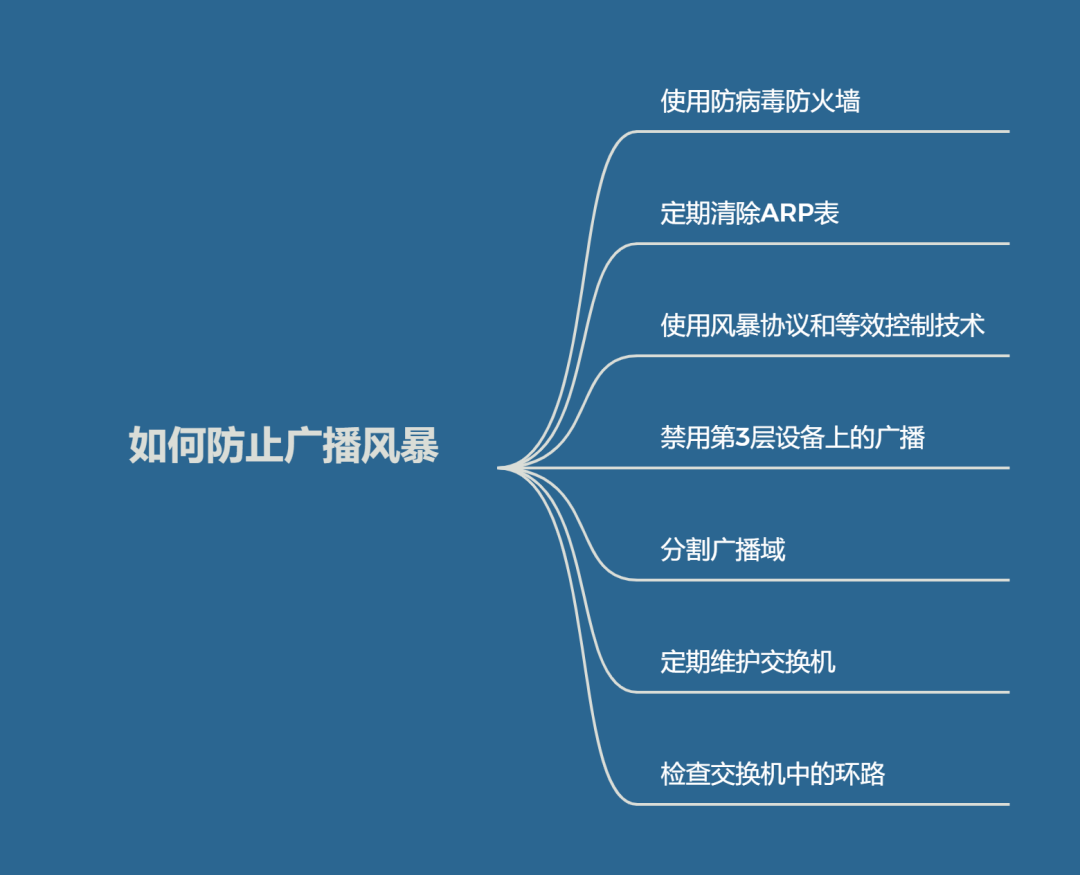
TOPSIS 算法的步骤如下:
- 创建一个包含M个样品和N个因子的评估矩阵 X。
- 将矩阵X正向化和标准化为矩阵Z(见下方)。
- 使用其他方法确定因子的权重Wj,如熵权法等。也可以默认所有因子权重相同。
- 在每个因子j中找出最劣(最小值)样品和最佳(最大值)样品 。
- 对于任意的样品 i,计算其和与之间的距离与 。
![图片[1]-TOPSIS综合评价法及其Python实现-不念博客](https://www.bunian.cn/wp-content/uploads/2024/02/image-15.png "TOPSIS综合评价法及其Python实现")
❝
权重可以如上式所示,在计算每个样品的 与 时独立添加。也可以在计算之前将权重直接和矩阵 相乘。❞
- 计算综合得分 。
![图片[2]-TOPSIS综合评价法及其Python实现-不念博客](https://www.bunian.cn/wp-content/uploads/2024/02/image-17.png "TOPSIS综合评价法及其Python实现")
正向化和标准化 Standardization
对于不同类型的因子,正向化的处理方式有所不同:
- 极大型指标保持不变。
- 极小型指标取倒数或负数。
- 中间型指标,若某个因子的最佳中间值为 ,则该因子下所有样品按下式处理:
![图片[3]-TOPSIS综合评价法及其Python实现-不念博客](https://www.bunian.cn/wp-content/uploads/2024/02/image-18.png "TOPSIS综合评价法及其Python实现")
- 区间型指标,若最佳区间为 ,则按下式进行转换:
![图片[4]-TOPSIS综合评价法及其Python实现-不念博客](https://www.bunian.cn/wp-content/uploads/2024/02/image-19.png "TOPSIS综合评价法及其Python实现")
式中M为:
![图片[5]-TOPSIS综合评价法及其Python实现-不念博客](https://www.bunian.cn/wp-content/uploads/2024/02/image-20.png "TOPSIS综合评价法及其Python实现")
完成正向化后,即可进行标准化或归一化。
代码
以下为 TOPSIS 算法的代码,使用了两种权重添加方法。
import numpy as np
import pandas as pd
from sklearn.datasets import make_regression
from sklearn.preprocessing import StandardScaler
def topsis(data, weights=0, use_weights=0):
'''
use_weights == 0 表明不使用权重
use_weights == 1 表明使用数据权重
use_weights == 2 表明使用方法权重
'''
data = np.array(data)
data = StandardScaler().fit_transform(data)
m, n = data.shape
if use_weights == 1: # # ! 加权方法 1
data = data * weights # 计算加权标准化矩阵
dataMax = data.max(axis=0) # 最优解
dataMin = data.min(axis=0) # 最劣解
D_max_ij = np.zeros([m,n])
D_min_ij = np.zeros([m,n])
# 计算距离
if use_weights == 2: # ! 加权方法 2
D_max_ij = ((dataMax - data) ** 2) * weights
D_min_ij = ((dataMin - data) ** 2) * weights
else:
D_max_ij = (dataMax - data) ** 2
D_min_ij = (dataMin - data) ** 2
D_max_i = np.sqrt(D_max_ij.sum(axis=1))
D_min_i = np.sqrt(D_min_ij.sum(axis=1))
S_i = D_min_i / (D_min_i + D_max_i)
return pd.DataFrame(S_i)
X, y = make_regression(n_samples=200, n_features=4, noise=0.5, random_state=10)
topsis(X, weights=(0.1, 0.5, 0.2, 0.2), use_weights=2)© 版权声明
本站文章由不念博客原创,未经允许严禁转载!
THE END