什么是缓存?
缓存就像是一个超快速的存储区域,保存了计算机或手机经常使用的内容的副本,这样可以在不访问较慢的主存储器的情况下快速获取。
一个现实中的例子可以是,每当我们购买杂货时,通常会倾向于大量购买,这样可以让杂货多存放一段时间,避免频繁去市场购买,这其实就是将杂货缓存在我们附近,而不是每次都从市场购买。
在系统设计中,如果缓存得当,它可以显著提升系统的性能。
缓存策略取决于数据访问模式,即数据是如何读取或写入的。
例如:
- 系统是读取密集型还是写入密集型?
- 系统是否需要高一致性?
等等……
因此,选择正确的写入缓存策略非常关键,下面是一些不同的缓存策略:
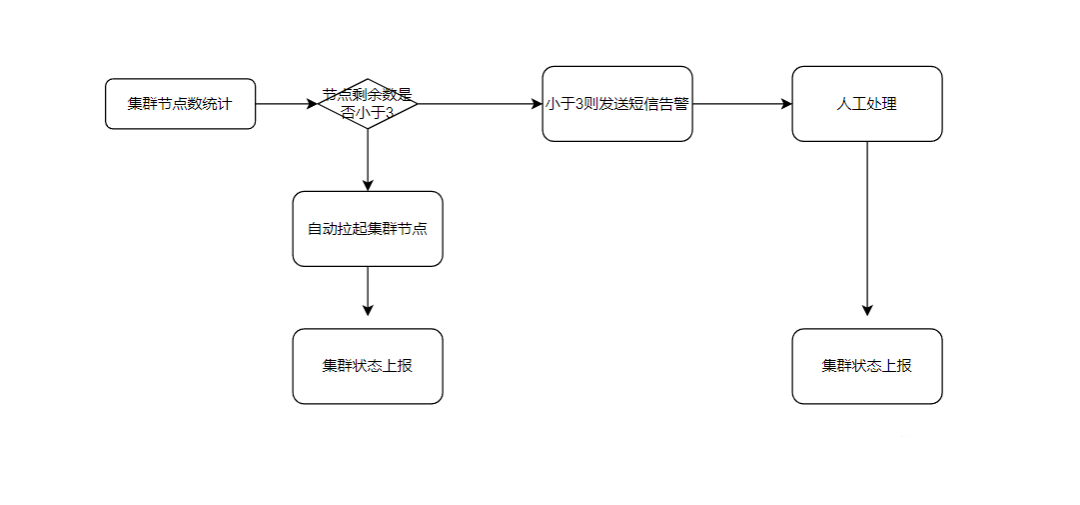
1. 缓存旁路(懒加载)
在这种设置中,应用程序缓存被分离出来,应用程序显式地与缓存和数据库一起工作。
这是一种技术,应用程序代码负责管理缓存。
当需要时,应用程序会将数据显式加载到缓存中,而缓存不会主动参与数据获取。
![图片[1]-什么是缓存,策略有哪些?-不念博客](https://www.bunian.cn/wp-content/uploads/2023/12/640-10-10.png "什么是缓存,策略有哪些?")
该图示了其工作原理。
使用场景:
适用于读取密集型系统,Redis 或 Memcached 非常受欢迎,我曾经在缓存旁路设置中使用过 Redis 以及 Mongo-db,效果非常显著。
这种读取技术可以与诸如写入旁路缓存之类的数据写入技术相结合,我接下来会解释。
优点:
灵活性:允许选择性缓存特定数据。
控制:应用程序控制数据何时加载到缓存中。
缺点:
提供过期数据:可能会提供过期数据,但如果我们实现了缓存的TTL(生存时间),则可以避免这种情况。
2. 写入旁路
跳过缓存,直接将数据写入数据库,并在读取用户请求的数据时更新缓存。
使用场景:
写入旁路可以与读取通过结合,对于数据写入一次,读取频率较低或几乎不读取的情况下提供良好的性能,例如实时日志或聊天室消息。
同样,这种模式也可以与缓存旁路结合使用。
3. 读取穿透缓存
读取穿透缓存是一种策略,当发生缓存未命中时,缓存会自动从底层数据源检索数据并填充自身。
这种技术与应用程序的数据访问层无缝集成,确保缓存与数据源保持同步。
![图片[2]-什么是缓存,策略有哪些?-不念博客](https://www.bunian.cn/wp-content/uploads/2023/12/640-11-9.png "什么是缓存,策略有哪些?")
使用场景、优点和缺点:
读取穿透缓存适用于读取密集的工作负载,当同一数据被多次请求时,例如,一个新博客。
缺点是,当首次请求数据时,总是会导致缓存未命中,并造成额外的数据加载开销。
4. 写入穿透缓存
写入穿透缓存是一种策略,其中写操作同时应用于缓存和底层数据源。
这确保了缓存和数据源保持同步,但与写入后缓存相比可能会引入额外的延迟,它同步应用更新。
![图片[3]-什么是缓存,策略有哪些?-不念博客](https://www.bunian.cn/wp-content/uploads/2023/12/640-12-10.png "什么是缓存,策略有哪些?")
使用场景、优点和缺点:
当与读取穿透缓存结合时,写入穿透缓存可以保证每次读取和写入的数据一致性。
但它会增加写操作的额外开销,因为每次写入都需要两次写入操作(缓存和数据库)。
它以异步方式应用更新。
5. 写入后缓存
写入后缓存,也称为写回缓存,涉及在写操作发生时延迟对数据源的更新。
系统不会立即更新底层存储,而是首先更新缓存,然后异步将更改传播到数据源。
![图片[4]-什么是缓存,策略有哪些?-不念博客](https://www.bunian.cn/wp-content/uploads/2023/12/640-13-10.png "什么是缓存,策略有哪些?")
使用场景、优点和缺点:
写回缓存提高了写入性能,非常适用于写入密集型任务。
当与读取穿透结合时,适用于混合工作负载,确保最近的数据可用。